聚类算法
本文共 686 字,大约阅读时间需要 2 分钟。
聚类算法
聚类算法属于机器学习或数据挖掘领域内,范畴比较小,一般都算作机器学习的一部分或数据挖掘领域中的一类算法,可结合机器学习进行学习
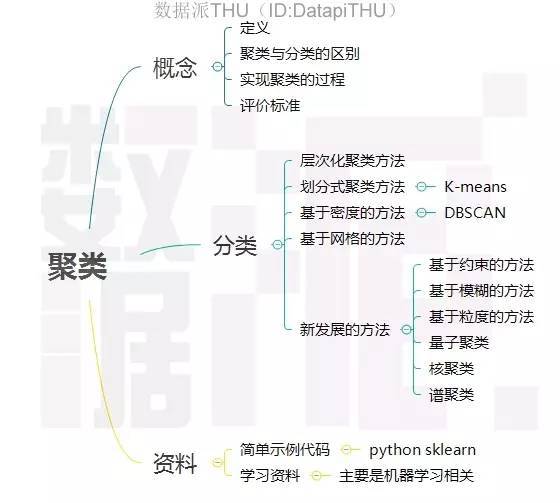
1.1 聚类的基本概念
聚类是数据挖掘中的概念,就是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
1.2 聚类和分类的区别
- Clustering (聚类),简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起;unsupervised learning (无监督学习)
- Classification (分类),对于一个classifier,通常需要你告诉它“这个东西被分为某某类”这样一些例子;supervised learning (监督学习)
1.3 聚类算法分类
层次化聚类算法, 又称树聚类算法,透过一种层次架构方式,反复将数据进行分裂或聚合。
划分式聚类算法,预先指定聚类数目或聚类中心,反复迭代逐步降低目标函数误差值直至收敛,得到最终结果。
基于模型的聚类算法, 为每簇假定了一个模型,寻找数据对给定模型的最佳拟合,同一”类“的数据属于同一种概率分布,即假设数据是根据潜在的概率分布生成的。
基于密度聚类算法,只要邻近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类
擅于解决不规则形状的聚类问题。
-基于网格的聚类算法,基于网格的方法把对象空间量化为有限数目的单元,形成一个网格结构。
转载地址:http://hdadi.baihongyu.com/
你可能感兴趣的文章
jvm高级特性整理
查看>>
SQL查询优化
查看>>
秒杀系统
查看>>
使用Jsoup抓取页面的数据
查看>>
时间工具类
查看>>
mybatis foreach
查看>>
微信验证域名
查看>>
Java实现微信JS-SDK【一】配置篇
查看>>
java合成图片
查看>>
httpclient 4.3.2 post get的工具类
查看>>
taskExecutor使用
查看>>
微信朋友圈分享
查看>>
eclipse安装JAVA反编译插件
查看>>
ip限制
查看>>
IE6 png 透明
查看>>
列表拖动排序
查看>>
select实例,拼音检索
查看>>
Spring MVC @Transactional注解方式事务失效的解决办法
查看>>
js正则表达式限制文本框只能输入数字,小数点,英文字母
查看>>
Spring事务失效的原因
查看>>